SEE IT IN ACTION 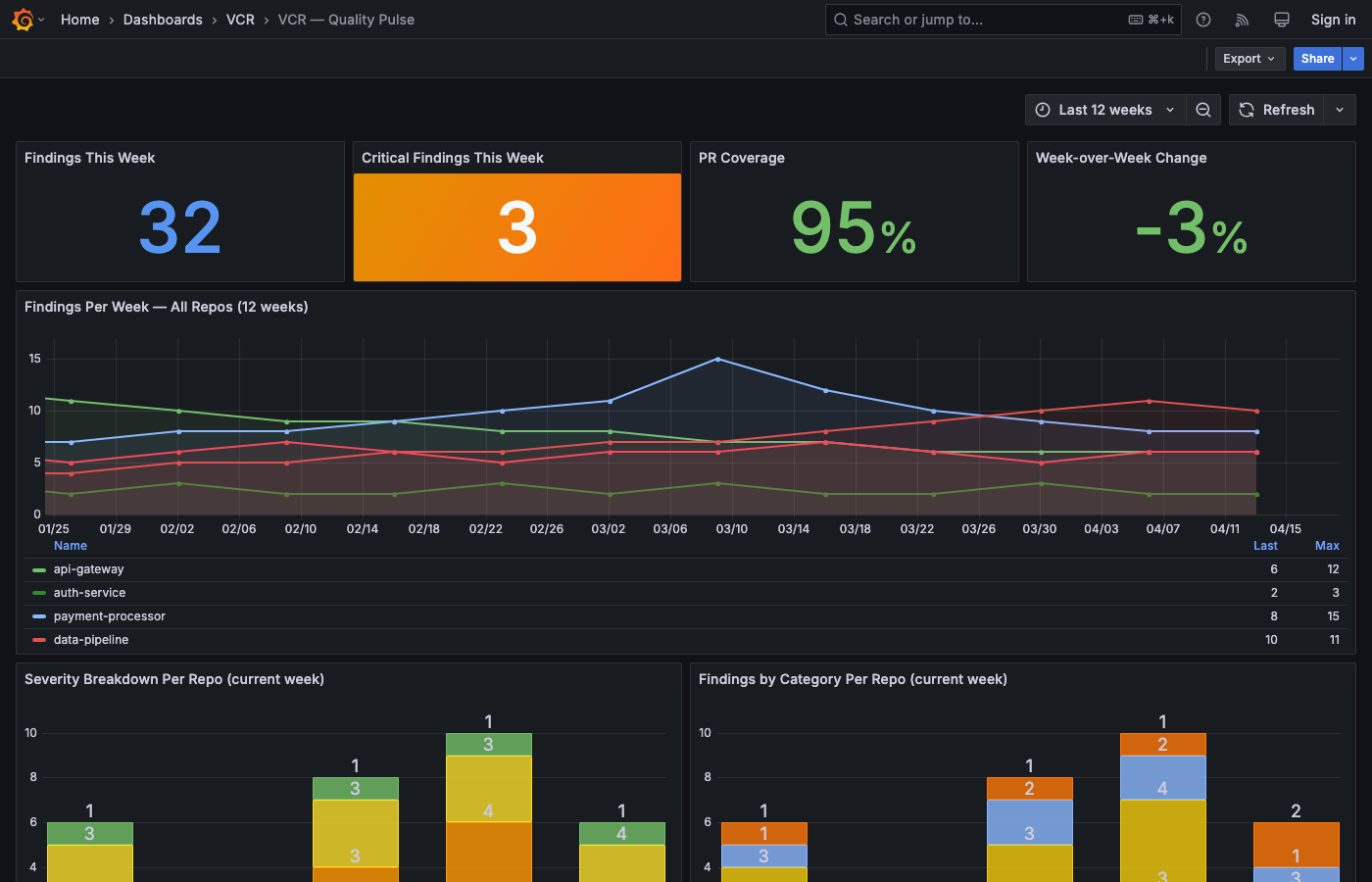
Interactive demo: real PRs, real findings
VCR reviews its own codebase on every pull request. Trace the triage flow, see what each layer catches, and follow findings back to the GitHub PR: 38 PRs, 154 findings.
A multi-layered, configuration-driven review process for enterprise teams shipping AI-generated code, where review policy lives in your repo as code. Part of the Visdom AI-Native SDLC.
Part of Visdom · VirtusLab's AI-Native SDLC
Your CI says the code is fine. Your tests pass. But the AI wrote the tests too.
One logged end-to-end run, three measurements. Numbers from logged runs, not projections.
Run context: 38 PRs · 154 findings
VCR is not a SaaS product and not a vendor service. It's a review process with an open-source reference implementation: opinionated patterns, a defined layer sequence, and a pipeline you run inside your own CI/CD, against your own LLM provider, behind your own network boundary.
VirtusLab deploys VCR as part of Visdom engagements: we embed with your platform engineers, configure the pipeline for your stack, tune the lenses to your conventions, and hand it over. Capability transfer from day one. Your team owns and operates the process. No ongoing SaaS dependency.
Evaluation methodology →Deployment model
Every PR passes through layers of increasing depth. Fast and cheap for trivial changes, thorough for risky ones. Measured across a 38-PR run: ~22 seconds per PR on average.
Full architecture reference →Risk scoring, routing. Instant.
Linters, SAST, pattern checks.
LLM review with full context.
Multi-pass analysis, security, arch.
Each PR gets a risk level based on path classification, diff size, coverage delta, and module stability.
Thresholds and routing rules live in a versioned .visdom.yaml in your repo, reviewed
and changed like any other code. Only MEDIUM+ risk triggers deep analysis.
Config, docs, deps. Auto-approved or light scan.
Business logic. Standard LLM review with context.
Security-sensitive, cross-service. Multi-pass analysis.
Auth, payments, data migration. Full depth + human gate.
Each review is fed pre-indexed knowledge about the codebase: ownership, dependencies, commit history, conventions, and test reliability data, plus your own standards documents, injected directly into the review context.
Explore the Context Fabric context engineContext sources
Patterns specific to AI-generated code that conventional CI and human reviewers typically miss. Each is a dedicated Review Lens in Layer 3. The same schema covers your own org rules: deterministic patterns and LLM checklists, side by side.
See real examples →Tests that mirror implementation instead of verifying behavior.
Calls to methods or endpoints that don't exist in your codebase.
AI-generated code that ignores your team's established patterns.
Unnecessary Factory patterns, abstractions, and complexity.
VCR reviews its own codebase on every pull request. Trace the triage flow, see what each layer catches, and follow findings back to the GitHub PR: 38 PRs, 154 findings.
Findings grouped by layer, linked to the exact line. Every comment names the rule, the risk level, and a concrete fix, not a vague hint.
confirmedBy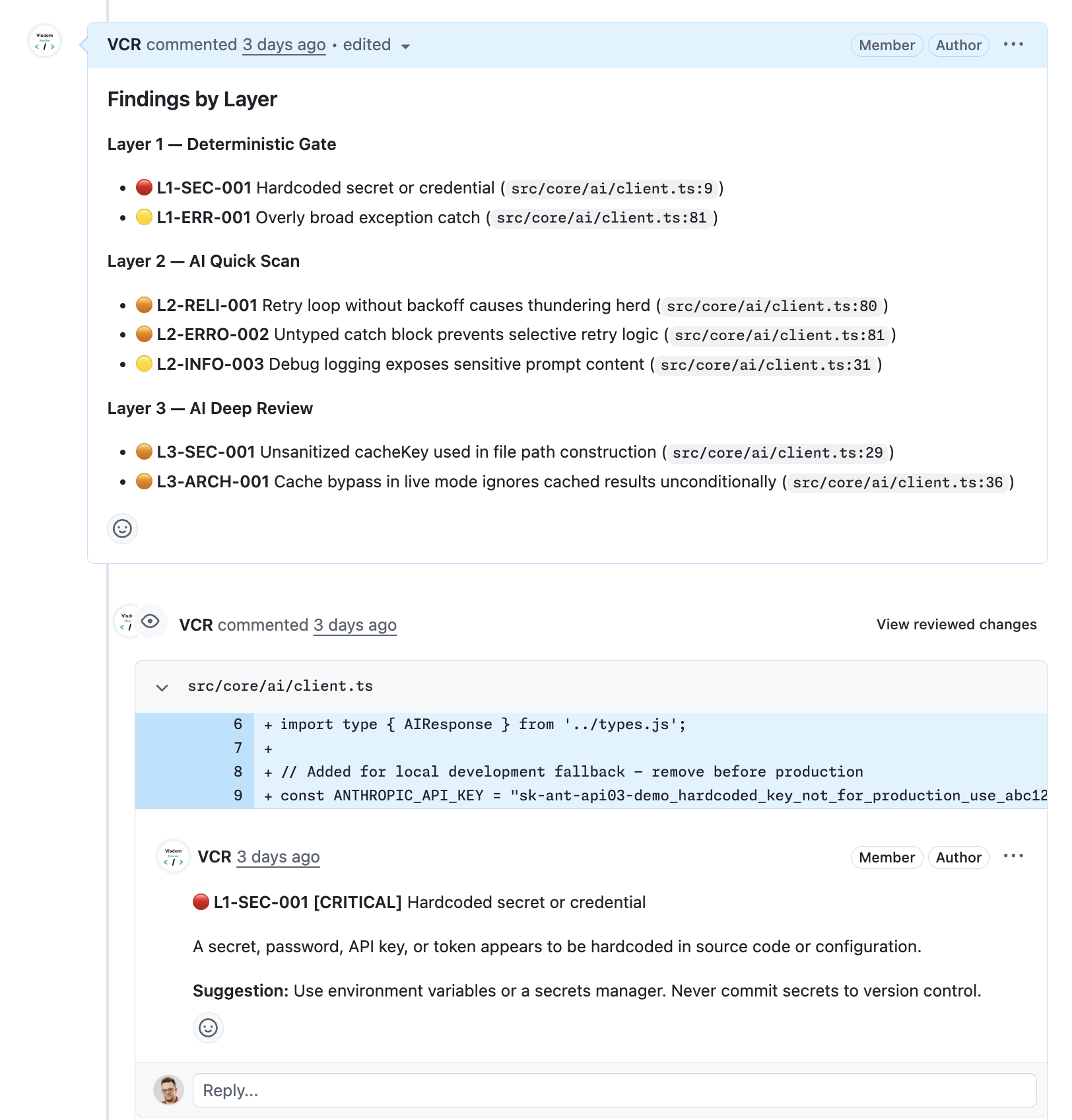
VCR is one of four components in Visdom, VirtusLab's AI-Native SDLC.
Pre-indexed code expertise, dependency graphs, PR history
Short CI loops, caching, incremental builds, test impact analysis
Multi-layered AI code review. You are here.
GovernanceAudit trail, auto-evaluation, EU AI Act compliance
Read the thinking behind it: The AI-Native SDLC series
Reference material, architecture docs, and real-world scenarios.
Architecture, configuration, metrics framework, and reference implementations.