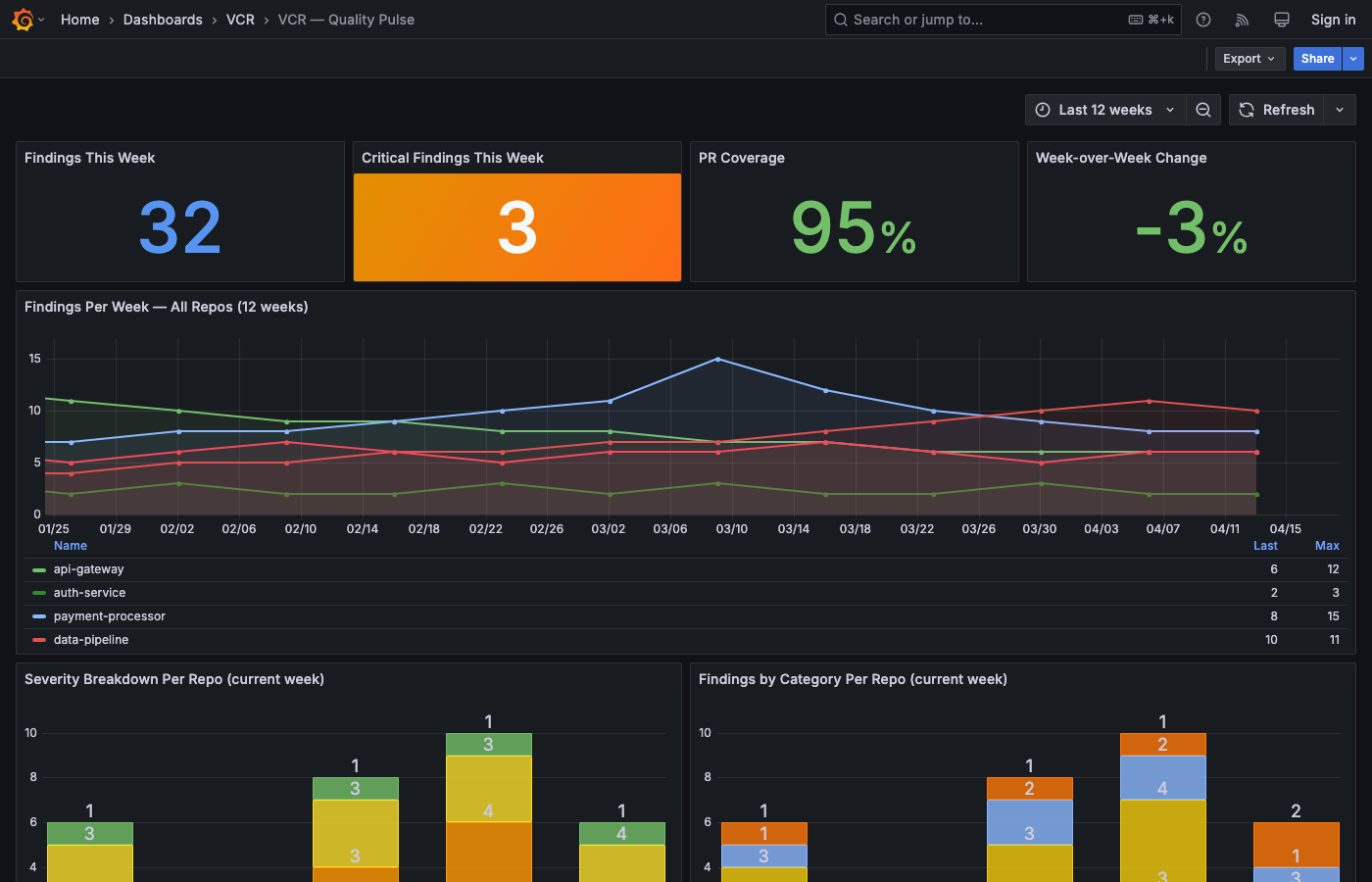
LIVE METRICS DASHBOARD
Team health — measured on every PR
Anonymous read access · updates on every PR · powered by Grafana on fly.io
VISDOM CREATED WITH VISDOM
We don't demo on toy examples. VCR runs on its own codebase — metacircularly — on every pull request. The findings below are real.
MEASURED METRICS — REAL RUNS
Per scenario · real run output
L0+L1 free · L3 only runs for HIGH/CRITICAL
50 PRs · 5 repos · advisor judge · honest numbers
Illustrative cost model — proportions vary by team
PR TRIAGE PATH — L0 → L1 → L2 → L3
Click a scenario to trace its path. Each layer shows what was found and why the gate made its decision.
← Select a scenario to trace its path
WHEN DOES THE HUMAN ENTER?
Click any scenario to see the full timeline. Click any event for details.
← Select a scenario
DEMO SCENARIOS — REAL RUNS, REAL FINDINGS
Every PR below passed CI, had a clean description, and claimed tests were green. VCR found the hidden issues anyway.
PR: feat: add retry and caching to AI client
"All existing tests pass."
Hardcoded API key, PII in logs, retry without backoff
PR: refactor: simplify deterministic gate pattern matching
"Behavior unchanged. All tests pass."
Weakened SQL check, timing-unsafe compare, SSRF rule disabled
PR: test: add comprehensive pipeline layer tests
"100% line coverage. All green."
15 tests mocking their own subjects — zero behavioral assertions
PR: feat: add payment processing endpoint
"Tested against Stripe sandbox. All passing."
SQL injection via f-string, card data in logs, weak JWT secret
PRODUCTION REPOSITORY RUN
The same engine, run end-to-end on llama3-java-hat — a real Java LLM-inference project by the site's author — with tool defaults and no config in the repo.
Deep review (L3) ran on 27 of 38 PRs — the cheap triage gate stopped the rest.
Config-as-code was then introduced in a single PR —
PR #50
— and the review of that PR used the configuration the PR itself carries:
a repo-specific regex rule fired (llama3/no-stdout-logging),
an LLM org rule fired with a ready-to-apply fix suggestion (llama3/tensor-ops-document-shape),
and a finding cited the repo's own docs/standards/error-handling.md.
4 findings · $0.0476 · 18.6 s
Actual review output:
PR #50 — demo: VISDOM config-as-code review showcase
4 files, +63/-0 lines
HIGH (2)
• InterruptedException swallowed without re-interrupt [src/main/java/com/arturskowronski/llama3babylon/hat/TensorDiagnostics.java]
• rowChecksum accepts float[] with no shape/dimension validation [src/main/java/com/arturskowronski/llama3babylon/hat/TensorDiagnostics.java]
MEDIUM (2)
• System.out logging in library code [src/main/java/com/arturskowronski/llama3babylon/hat/TensorDiagnostics.java]
• rowChecksum accepts any-length array with no dimension guard [src/main/java/com/arturskowronski/llama3babylon/hat/TensorDiagnostics.java]
Duration: 18.6s · Cost: $0.0476 · L3: yes
The full SARIF export for this review is vendored at
docs/demos/llama3-v8/review.sarif
for readers wiring code-scanning tooling.
The review comments visible on the PR itself come from a separate run of the same engine,
which found 3 of these 4 findings — the deterministic layers agree run to run; the LLM lenses do not always.
LIVE METRICS DASHBOARD
Anonymous read access · updates on every PR · powered by Grafana on fly.io